Le Test03 a pour but de voir s'il existe une loi du second élément large dans l'acte de lecture, au moment du déchiffrage systématique .
L'observation des erreurs de lecture du Test02 a permis de montrer qu'il y a différents types de déchiffrage. Le premier, le déchiffrage systématique, semble être conditionné par une recherche de fluidité (un item après l'autre, tant qu'il n'y a pas d'interférences).
Cette fluidité peut être perturbée par la présence d'un élément plus éloigné mais plus attractif. Cette notion d'attraction, toujours selon les faits linguistiques observés, semble dépendre d'un "poids visuel" de chaque gramme.
Cette notion de "poids visuel" correspond à la surface totale d'un gramme.
Pour cela, j'ai dû calculer la surface (que je préfère pour des raisons théoriques appeler "poids visuel") de chaque gramme (on reste dans la même isotopie sémantique ! ) en imprimant sur papier millimétré chaque lettre de l'alphabet (police time news roman) en taille ... 200 ! avec l'atttribut contour.
Ensuite, j'ai compté un à un chaque millimètre carré...
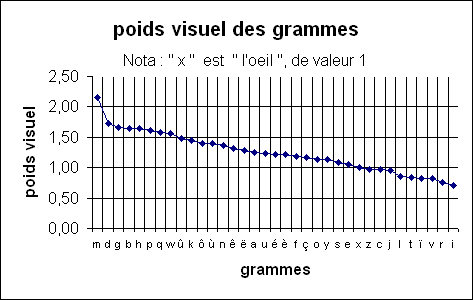
Dans un premier temps, on a donc la surface brute (par exemple 510 mm2 pour le gramme "b", 365 mm2 pour " f ", etc.). Mais comme cette surface brute n'a pas de valeur représentative en soi, j'ai pris l' "oeil" de référence des typographes (à savoir la lettre "x") à laquelle j'ai donné la valeur étalon 1 ("x" fait 310 mm2 en time news roman taille 200). Avec une banale règle de trois, j'ai pu enfin classer par ordre décroissant les grammes selon leur poids visuel (on a ainsi : m, d, g, b, h, p, q, w, û, k, etc.).
Ce résultat m'a donc permis de concevoir le test03.
L'hypothèse (embrayée par des observations sur le terrain) est qu'un pseudo-mot comme "damu" aura plus de risques d'être lu "madu" que l'inverse, à cause du poids visuel (et attractif pour l'oeil) de "m" bien supérieur à "d" ("m" : 2,15 ; "d" : 1,75). Ce point pourrait intéresser plus particulièrement les dyslexiques.
Pour ce test03, j'ai fabriqué des pseudo-mots de façon à éviter certains pièges (par exemple une proximité sémantique, le pseudo-mot devenant alors une amorce, ce qui fausserait le test).

Lecture, apprentissage, mécanismes, processus cognitifs, acquisition, langue, langage, décodage, déchiffrage, décryptage, didactique, pédagogie, lecture, apprentissage, mécanismes, processus cognitifs, acquisition, langue, langage, décodage, déchiffrage, décryptage, didactique, pédagogie
Nombre de visiteurs depuis 2001
La charte graphique de ce site a été entièrement refondue en juillet 2011
Citez vos sources !
Citez vos sources !
Citez vos sources !
Citez vos sources !
Citez vos sources !
Citez vos sources !
Citez vos sources !
Citez vos sources !
Bonne navigation. Contactez-moi pour avoir des copies de certains contenus. Jean-Marc Muroni